
README.md 22 KB
Amazon S3 MultiThread Resume Migration Cluster Solution (Amazon S3多线程断点续传迁移集群方案)
PROJECT LONGBOW - Amazon EC2 Autoscaling 集群,支撑海量文件于海外和中国Amazon S3之间传输
Cluster & Serverless Version 0.98
架构图如下:
Amazon S3 新增文件触发传输:
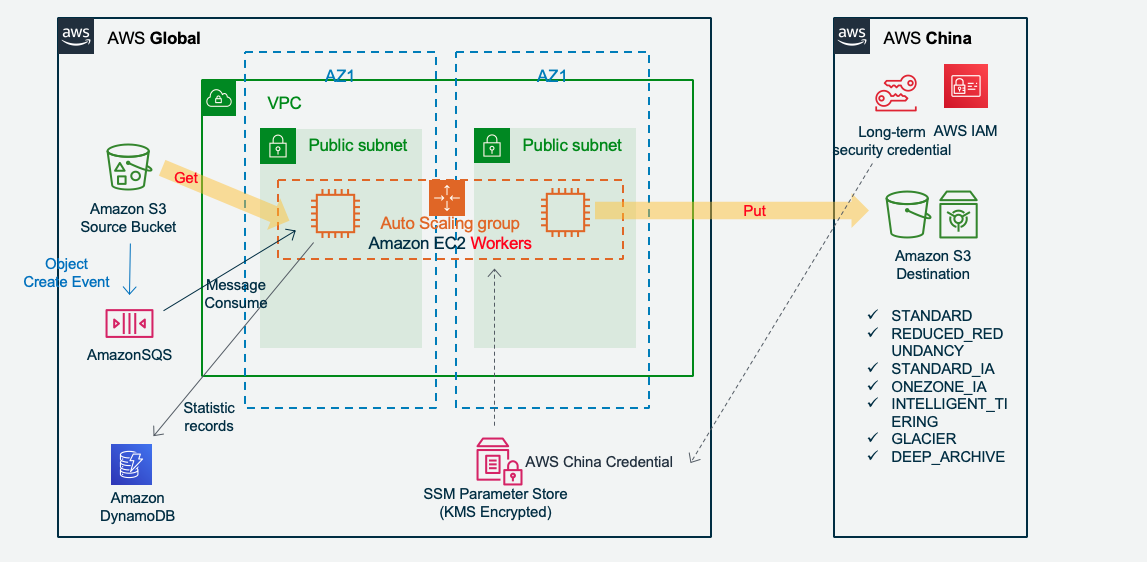
Jobsender 扫描 Amazon S3 派发传输任务:
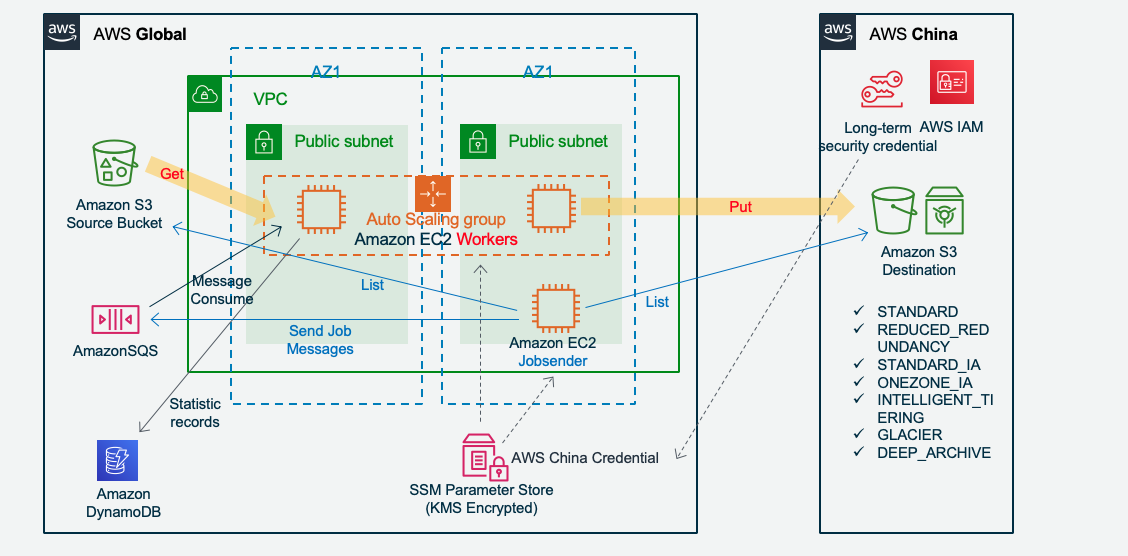
如果需要定时运行Jobsender任务,可以登录EC2设置定时任务(crontab -e 命令)运行s3_migration_cluster_jobsender.py。
特点
- 海外和国内Amazon S3互传:集群版适用于海量文件传输,无服务器版适合不定期突发传输。
- 快速且稳定:多节点 X 单节点多文件 X 单文件多线程,支撑海量巨型文件并发传输。启用BBR加速。自动区分大小文件和 0 Size 文件走不同流程。
- 可靠:Amazon SQS 消息队列管理文件级任务,断点续传,超时中断保护。每个分片MD5完整性校验。Single Point of True,最终文件合并以S3上的分片为准,确保分片一致。
- 安全:内存转发不写盘,传输SSL加密,开源代码可审计,采用IAM Role和利用ParameterStore加密存储AcceesKey。
- 可控运营:任务派发与传输速度相匹配,系统容量可控可预期;Amazon DynamoDB和SQS读写次数只与文件数相关,而与文件大小基本无关;日志自动收集;AWS CDK自动部署;
- 弹性成本优化:集群自动扩展,结合 Amazon EC2 Spot节省成本;无服务器Lambda只按调用次数计费;支持直接存入Amazon S3各种存储级别,节省长期存储成本。
- 可以与无服务器 AWS Lambda 版本一起运行,支持混合流量
工作原理
流程
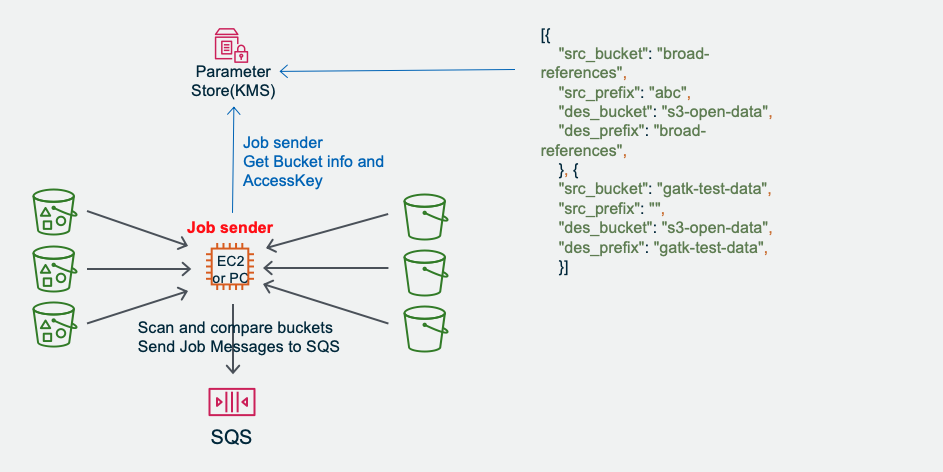
预备阶段(可选):Jobsender 获取源和目的 Bucket List并比对差异,形成Job List。并定期进行。
Jobsender 发送 Job messages to SQS (每个 job 是Amazon S3上的一个文件),并记录到 DDB (仅做统计进度) Amazon S3 新增也可以直接触发Amazon SQS
Amazon EC2 or/and Lambda 从SQS获取Job. 每个EC2 instance获取多个Job,每个Lambda runtime获取一个Job
Amazon EC2 or/and Lambda 对每个Job创建多线程,每个线程各自获取文件分片,并上传到目标 S3
- Amazon EC2和Lambda可以分用也可以同时工作,各自取SQS Job,但要注意SQS的超时时间设定
任务启动四种方式之一
Job Sender 去List多个源和目的桶进行比对
Amazon S3新增文件,直接触发Amazon SQS
批量任务完成后,Job Sender 再次List比对
定时任务触发Job Sender进行比对
四种启动方式示意图:
性能与可控运营
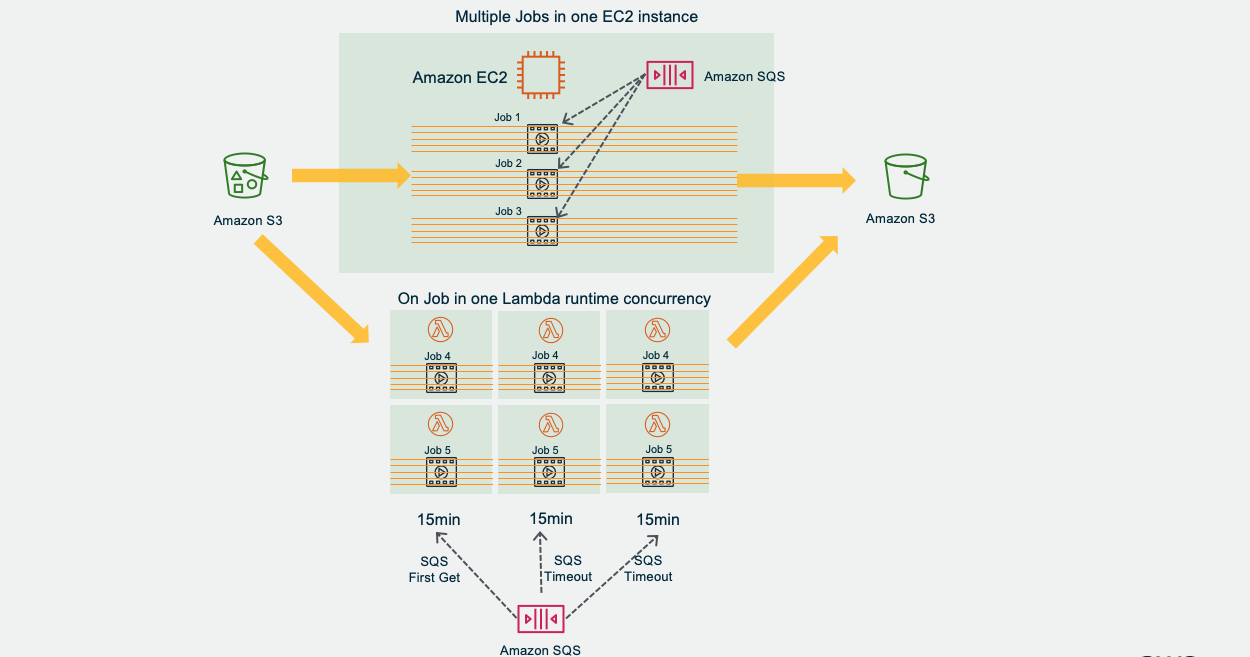
- 单Worker节点并发多线程从Amazon SQS获取多个文件任务,每个文件任务只会被一个Worker获得。Worker对每个任务并发多线程进行传输,这样对系统流量更可控,稳定性比把一个文件分散多节点要高,也不会出现一个大文件就堵塞全部通道,特别适合大量大文件传输。
- 服务器内置并启用 TCP BBR 加速,实测比默认的Cubic模式快约2.5倍。
- 多机协同,吞吐量叠加
- 建议集群部署在源S3相同Region,并启用 VPC S3 Endpoint。
- 在Amazon DynamoDB中记录工作节点和进度,清晰获知单个文件工作状态,传输一次文件Job只需要写2-4次DynamoDB。
- 设置 SSM ParaStore/Lambda Env 即可调整要发送Job的Bucket/Prefix,无需登录服务器
性能测试
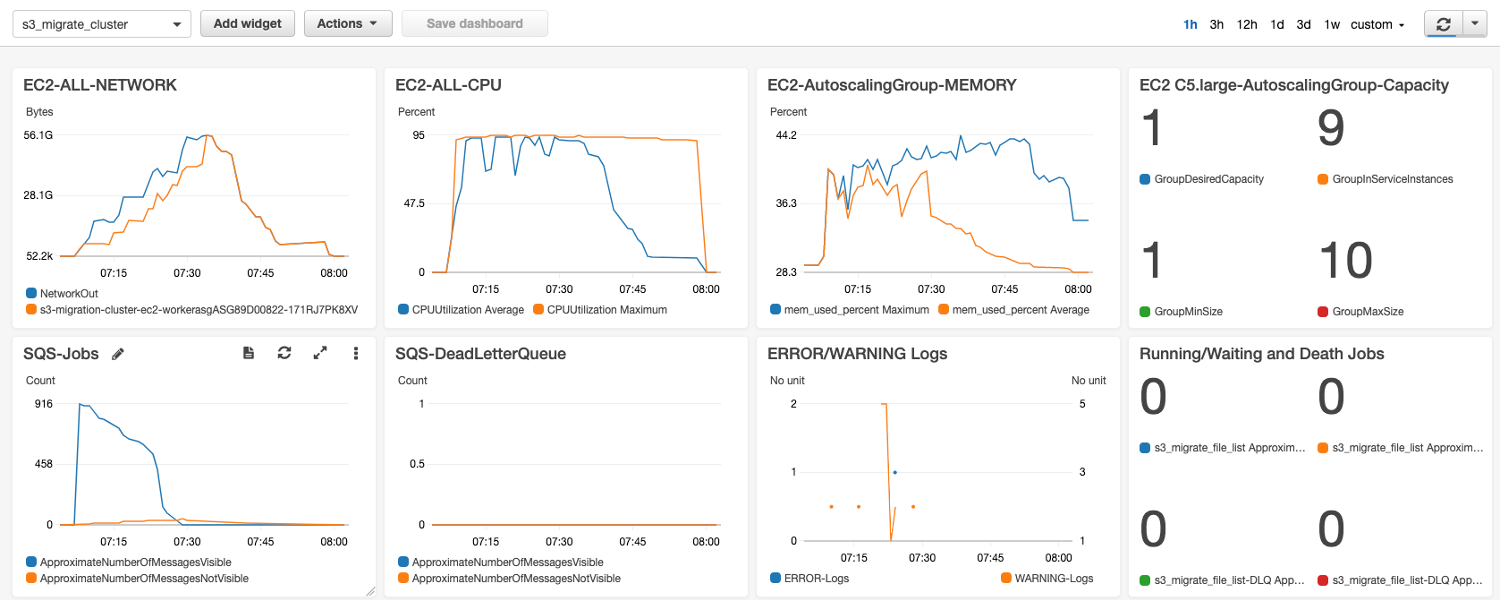
测试结果,对于大量的GB级文件,单机 c5.large(该测试设置 5 文件 x 30 线程)可达到跨境 800Mbps以上带宽吞吐。如文件是MB级,则可以设置单节点并发处理更多的文件。上图中可以看到 Autoscaling Group 在逐步增加EC2,多机吞吐叠加,9台 Autoscale 吞吐线性叠加达到900+MB/s (7.2Gbps)。传输 1.2TB 数据 (916个文件) 只用了1小时,从 us-east-1 到 cn-northwest-1。并且在传输完成时自动关闭了服务器,只留下了一台。
 各种文件大小的用时统计:
各种文件大小的用时统计:
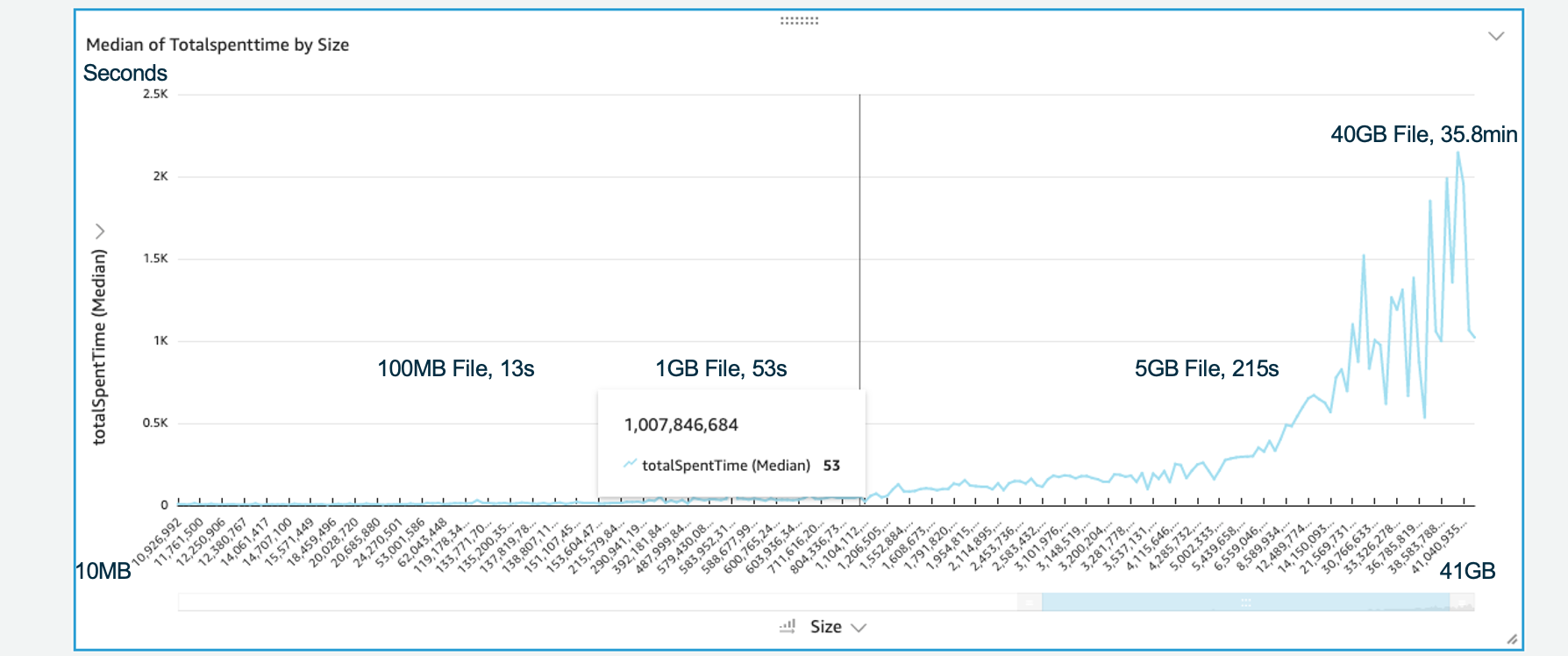
- 100MB File 13 秒
- 1GB File 53 秒
- 5GB File 215 秒
- 40GB File 35.8 分钟
Notice: Autoscale 新增的 EC2 的指标在5分钟之后,才会被纳入该 Autoscaling Group EC2 Network 指标,所以上图看起来 All EC2 Network 指标显得更实时。
可靠与安全性
- 每个分片传输完成都会在Amazon S3上做MD5完整性校验。
- 多个超时中断与重试保护,保证单个文件的送达及时性:
Amazon EC2 worker上有任务超时机制,s3_migration_cluster_config.ini 中默认配置1小时
Amazon SQS 消息设置 Message InvisibleTime 对超时消息进行恢复,驱动节点做断点重传,建议与Worker超时时间一致。如果混合集群和Serverless架构,则以时间长的那方来设置InvisibleTime
Amazon SQS 配置死信队列DLQ,确保消息被多次重新仍失败进入DLQ做额外保护处理。CDK中默认配置24次。 - Single point of TRUE:把最终S3作为分片列表的管理,合并文件时缺失分片则重新传。
- 建议一批次任务在全部任务完成后,运行jobsender进行List比对。或定期运行核对源和目的S3的一致性。
- 文件分片只经worker内存缓存即转发,不去占I/O写本地磁盘(速度&安全)
- 传输为Amazon S3 API: SSL加密传输
- 开源代码,可审计。只使用 AWS SDK 和 Python3 内置的库,无任何其他第三方库。
- 一侧Amazon S3访问采用IAM Role,另一侧Amazon S3访问的access key保存在SSM ParaStore中(KMS加密),或Lambda的EnvVar(KMS加密),不在代码或配置文件保存任何密钥
弹性成本
- Amazon EC2 worker Autoscaling Group 处自动扩展和关机
- 使用了 Amazon Spot Instances 降低成本,Worker节点无状态,可承受随时中断
- Amazon EC2 jobsender&worker 允许合一部署,如果需要。另外,如果任务不多,jobsender还可以配置在管理员的PC电脑上,需要时才运行。
- 可以同时运行 AWS Lambda Serverless 处理不定期,突发任务
- 可根据自己的场景测试寻找最佳性价比: 调整最低配置Amazon EC2 Type和AWS Lambda Memory Jobs/node * Threads/Jobs * Nodes 组合,包括考虑:数据传送周期、文件大小、批次大小、可容忍延迟、成本
- 存入目标Amazon S3 存储级别可直接设置 IA, Deep Archive 等
部署
1. 前置配置
请在 AWS CDK 部署前手工配置 System Manager Parameter Store 新增这个参数
名称:s3_migration_credentials
类型:SecureString
级别:Standard
KMS key source:My current account/alias/aws/ssm 或选择其他你已有的加密 KMS Key
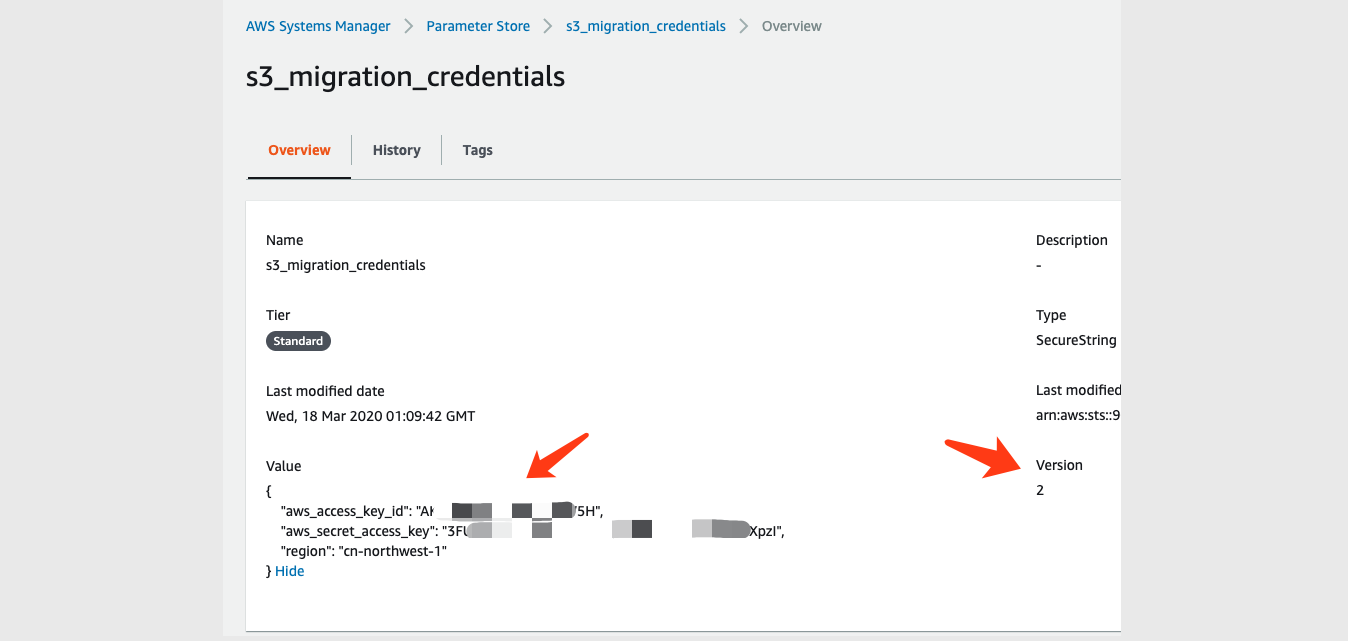
这个 s3_migration_credentials 是用于访问跟EC2不在一个账号系统下的那个S3桶的访问密钥,在目标Account 的IAM user配置获取。配置示例:{ "aws_access_key_id": "your_aws_access_key_id", "aws_secret_access_key": "your_aws_secret_access_key", "region": "cn-northwest-1" }配置示意图:
配置 AWS CDK 中 app.py 你需要传输的源S3桶/目标S3桶信息,示例如下:
[{ "src_bucket": "your_global_bucket_1", "src_prefix": "your_prefix", "des_bucket": "your_china_bucket_1", "des_prefix": "prefix_1" }, { "src_bucket": "your_global_bucket_2", "src_prefix": "your_prefix", "des_bucket": "your_china_bucket_2", "des_prefix": "prefix_2" }]这些会被AWS CDK自动部署到 System Manager Parameter Store 的 s3_migration_bucket_para
配置告警通知邮件地址在 cdk_ec2stack.py
如果有需要可以修改默认的 ./cdk-cluster/code/s3_migration_cluster_config.ini 配置(例如JobType,或者并发线程数),CDK会自动部署代码和配置文件到新建的一个s3-migration-cluster-resourc-deploybucket桶。在部署完成后,也可以再次修改配置文件,重新上传S3同样的位置。新启动的EC2就会在Userdata中下载新的配置文件。
2. CDK自动部署
CDK 会自动化部署以下所有资源除了 1. 前置配置所要求手工配置的Key:
Amazon VPC(含2AZ,2个公有子网) 和 S3 Endpoint,
Amazon SQS Queue: s3_migrate_file_list
Amazon SQS Queue DLQ: s3_migrate_file_list-DLQ,
Amazon DynamoDB 表: s3_migrate_file_list,
Amazon EC2 JobSender Autoscaling Group with only 1 instance: t3.micro,
Amazon EC2 Workers Autoscaling Group capacity 1-10: c5.large 可以在 cdk_ec2_stack.py 中修改,
Amazon EC2 Autoscaling Policy
Amazon SSM Parameter Store: s3_migration_bucket_para 作为S3桶信息给Jobsender去扫描比对
Amazon EC2 所需要访问各种资源的 IAM Role
Amazon CloudWatch Dashboard 监控
Amazon CloudWatch Alarm 自动Email告警
Amazon S3 Bucket - s3-migration-cluster-resource-newbucket 新增内容桶,新增内容自动触发SQS,所有新存入的对象都会被传输
Amazon S3 Bucket - s3-migration-cluster-resourc-deploybucket 代码部署桶,这个桶是给部署的时候CDK上传应用程序代码的,每个EC2启动的时候都会从这个桶下载代码。如果要修改配置文件,可以直接在这个桶修改。Amazon EC2 User Data 自动安装 CloudWatch Logs Agent 收集 EC2 初始化运行 User Data 时候的 Logs,以及收集 s3_migrate 程序运行产生的 Logs
Amazon EC2 User Data 自动启用 TCP BBR
Amazon EC2 User data 自动拉 github 上的程序和默认配置,并自动启动。建议把程序和配置放你自己的S3上面,让user data启动时拉取你修改后的配置,或者使用你自己打包的AMI启动EC2。
如果有需要可以修改 Amazon EC2 上的配置文件 s3_migration_config.ini 说明如下:
* JobType = PUT 或 GET (default: PUT) 决定了Worker把自己的IAM Role用来访问源还是访问目的S3, PUT表示EC2跟目标S3不在一个Account,GET表示EC2跟源S3不在一个Account * Des_bucket_default/Des_prefix_default 是给Amazon S3新增文件触发Amazon SQS的场景,用来配置目标桶/前缀的。 对于Jobsender扫描S3并派发Job的场景,不需要配置这两项。即使配置了,程序看到SQS消息里面有就会使用消息里面的目标桶/前缀 * table_queue_name 访问的Amazon SQS和DynamoDB的表名,需与CloudFormation/CDK创建的ddb/sqs名称一致 * ssm_parameter_bucket 在AWS SSM ParameterStore 上保存的参数名,用于保存buckets的信息,需与CloudFormation/CDK创建的 parameter store 的名称一致 * ssm_parameter_credentials 在 SSM ParameterStore 上保存的另一个账户访问密钥的那个参数名,需与CloudFormation/CDK创建的 parameter store 的名称一致 * StorageClass = STANDARD|REDUCED_REDUNDANCY|STANDARD_IA|ONEZONE_IA|INTELLIGENT_TIERING|GLACIER|DEEP_ARCHIVE 选择目标存储的存储类型, default STANDARD * ResumableThreshold (default 5MB) 单位MBytes,小于该值的文件,则开始传文件时不走Multipart Upload,不做断点续传,节省性能 * MaxRetry (default 20) API Call在应用层面的最大重试次数 * MaxThread (default 20) 单文件同时working的Thread进程数量 * MaxParallelFile (default 5) 并行操作文件数量 * JobTimeout (default 3600) 单个文件传输超时时间,Seconds 秒 * LoggingLevel = WARNING | INFO | DEBUG (default: INFO) * 不建议修改:ifVerifyMD5Twice, ChunkSize, CleanUnfinishedUpload, LocalProfileMode * 隐藏参数 max_pool_connections=200 在 s3_migration_lib.pyJobsender 启动之后会检查Amazon SQS 是否空,空则按照 Parameter Store 上所配置的 s3_migration_bucket_para 来获取桶信息,然后进行比对。如果非空,则说明前面还有任务没完成,将不派送新任务。
手工配置时,注意三个超时时间的配合: Amazon SQS, EC2 JobTimeout, Lambda,CDK 默认部署是SQS/EC2 JobTimeout为1小时
监控与自动伸缩
CDK 已经自动部署了 CloudWatch Dashbard:
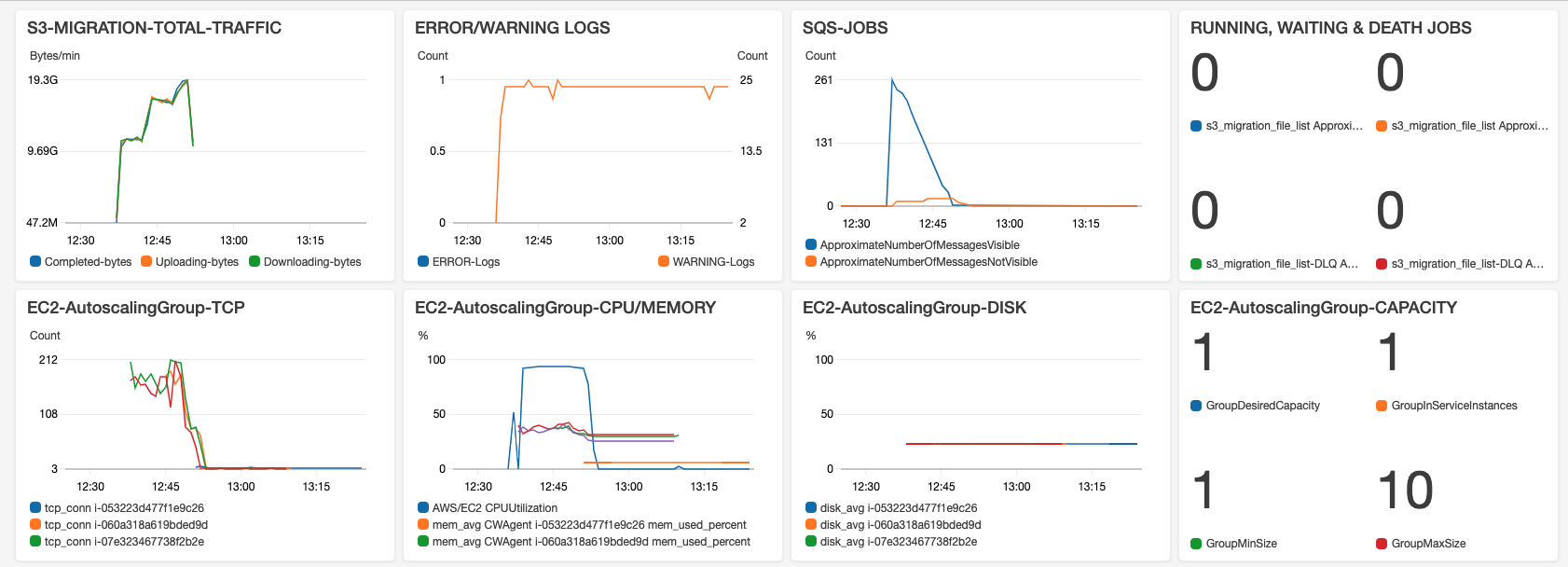
- TRAFFIC:Worker 在下载、上传、完成每个分片的时候都会写 Logs,这些日志会被 CloudWatch Agent 收集并发送到 CloudWatch Logs,这里设置了 LogGroup Filter 将日志中带下载、上传、完成标记的日志捕获,并展现其每分钟传输的 Bytes
- ERROR/WARNING LOGS:应用在遇到错误或警告信息,会写入 Logs,与上面相同的原理被捕获和展现。出现 ERROR 或 WARNING 日志时,可以在 LogGroup 中搜索相应的日志进行定位分析。
- SQS-JOBS:
RUNNING 是 Amazon SQS 队列监控多少是正在进行的 ( Messages in Flight )
WAITING 即多少任务在排队 ( Messages Available )
DEATH 即死信队列 s3_migrate_file_list-DLQ 收集在正常队列中处理失败超过次数的消息(默认配置重试24次),出现 DLQ 会触发 SNS 告警邮件。 - Amazon EC2 Autoscaling Group TCP 每台服务器的连接数,通过 CloudWatch Agent 收集。
- Amazon EC2 Autoscaling Group CPU 总的平均占用率
- Amazon EC2 Autoscaling Group MEMORY,每台服务器的内存占用率,通过 CloudWatch Agent 收集。
- Amazon EC2 Autoscaling Group DISK,每台服务器的磁盘占用率,通过 CloudWatch Agent 收集。注意如果满了会导致应用写日志失败而退出。如果 Autoscaling Group 策略设置合理,经常伸缩,则由于旧服务器会被终止,所以不必担心日志满。
- Autoscaling Group CAPACITY 实例数量,这个值需要你手工到 EC2 控制台 Autoscaling 菜单的 Monitor 分页,去 Enable "Group Metrics Collection" 功能才能收集到。
- Autoscaling Up: AWS CDK 创建了基于 SQS 队列 Messages Available 的 Alarm,5 分钟大于 100 消息触发 Autoscaling 增加 1 台EC2,超过 500 消息则直接增加 2 台。
- Autoscaling Shut Down: 队列中无消息时会将 EC2 数量降到 1。实现方式是:AWS CDK 创建了表达式 Expression: SQS Messages Available + Messages in Flight = 0 ,并且 EC2 数量大于1,则触发自动缩减 EC2 数量直接设为 1,并同时发送 SNS 告警 EMAIL 通知。这个告警可以作为批量传输完成后的通知,而且这样设置了 EC2 当前数量的判断,于是只会在一批次缩减的时候通知一次,而不会不停地每15分钟通知一次。你也可以根据场景需求,把这里自动设置为 0 ,即一次性关闭全部。EC2 当前数量这个值来自 Autoscaling Group CAPACITY,需要你手工到 EC2 控制台 Autoscaling 菜单的 Monitor 分页,去 Enable "Group Metrics Collection" 功能才能收集到。
- 以上 Autoscaling 和 Alarm 都会在 CDK 中创建。请在 cdk_ec2_stack 中设置告警的 EMAIL 地址
- Amazon DynamoDB 表可以有详细的每个文件传输任务的完成情况,启动时间,重试次数等,可以作为后续统计分析的基础
文件过滤模式
Jobsender 比对S3 Bucket时候可以设置忽略某个文件,或某前缀/某后缀的一批文件,编辑 s3_migration_ignore_list.txt 增加你要忽略对象的 bucket/key,一个文件一行,可以使用通配符如 "*"或"?",例如:
your_src_bucket/your_exact_key.mp4 your_src_bucket/your_exact_key.* your_src_bucket/your_* *.jpg */readme.md
TCP BBR 提高网络性能
CDK 默认部署时启动了 Amazon EC2 服务器上的 TCP BBR: Congestion-Based Congestion Control,提高传输效率
Amazon Linux AMI 2017.09.1 Kernel 4.9.51 or later version supported TCP Bottleneck Bandwidth and RTT (BBR) .
改为 GET 模式
当前目录下的CDK配置的是按PUT模式配置。改变为GET模式只需修改:
cdk_ec2_stack.py 里面这一段,即把src_bucket换成des_bucket,并且允许EC2读写现有S3:
# Allow EC2 access exist s3 bucket for GET mode: read and write access the destination buckets # bucket_name = '' # for b in bucket_para: # if bucket_name != b['des_bucket']: # 如果列了多个相同的Bucket,就跳过 # bucket_name = b['des_bucket'] # s3exist_bucket = s3.Bucket.from_bucket_name(self, # bucket_name, # bucket_name=bucket_name) # s3exist_bucket.grant_read_write(jobsender) # s3exist_bucket.grant_read_write(worker_asg)另外,注意 s3_migration_cluster_config.ini 设置为 JobType = GET
Amazon S3 版本控制支持
为什么要启用 S3 版本控制
如果不启用S3版本控制,在大文件正在传输的过程中,如果此时原文件被新的同名文件替换,会导致复制的文件部分是老的文件,部分是新的文件,从而破坏了文件的完整性。以前做法是强调不要在传输过程中去替换源文件,或者只允许新增文件。
而对于无法避免会覆盖源文件的场景下,可以启用S3版本控制,则可以避免破坏文件完整性的情况。本项目已支持S3版本控制,需要配置:
- 对源文件的S3桶“启用版本控制”(Versioning)
- 源S3桶必须开放 ListBucketVersions, GetObjectVersion 这两个权限
以及设置以下的配置参数,分不同场景说明如下
支持S3 版本控制的配置参数
JobsenderCompareVersionId(True/False):
默认 Flase。
True意味着:Jobsender 在对比S3桶的时候,对源桶获取对象列表时同时获取每个对象的 versionId,来跟目标桶比对。目标桶的 versionId 是在每个对象开始下载的时候保存在 DynamoDB 中。Jobsener 会从 DynamoDB 获取目标桶 versionId 列表。Jobsender发给SQS的Job会带上versionId。UpdateVersionId(True/False):
默认 Flase。
True意味着:Worker 在开始下载源文件之前是否更新Job所记录的versionId。这功能主要是面向 Jobsender 并没有送 versionId 过来,但又需要启用 versionId 的场景。GetObjectWithVersionId(True/False):
默认 Flase。
True意味着:Worker 在获取源文件的时候,是否带 versionId 去获取。如果不带 versionId 则获取当前最新文件。
对于Cluster版本,以上参数都在配置文件 s3_migration_config.ini 对于Serverless版本,以上参数分别在 Lambda jobsender 和 worker Python 文件的头部,内部参数定义的位置
场景
S3新增文件触发的SQS Jobs:
UpdateVersionId = False GetObjectWithVersionId = TrueS3新增文件直接触发SQS的情况下,S3启用了版本控制功能,那么SQS消息里面是带 versionId 的,Worker 以这个versionId 去 GetObject。如果出现中断,恢复时仍以该 versionId 去再次获取。 如果你没有GetObjectVersion 权限,则需要把这两个开关设False,否则会因为没权限而获取文件失败 (AccessDenied)。
Jobsender比对S3发送SQS Jobs这里又分两种目的:
完整性:为了绝对保证文件复制过程中,即使被同名文件覆盖,也不至于文件半新半旧。
JobsenderCompareVersionId = False UpdateVersionId = True GetObjectWithVersionId = True为了比对速度更快,所以在比对的时候不获取versionId,这样发送SQS的 versionId 是 'null' 在 Get object 之前获取真实 versionId,并写入 DynamoDB,完成传输之后对比DDB记录的 versionId 。在文件传输结束时,再次校验 DynamoDB 中保存的 versionId,如果因为发生中断重启,而刚好文件被替换,此时versionId会不一致,程序会重新执行传输。
完整性和一致性:为了对比现存源和目的S3的文件不仅仅Size一致,版本也要一致性。并绝对保证文件复制过程中,即使被同名文件覆盖,也不至于文件半新半旧。
JobsenderCompareVersionId = True UpdateVersionId = False GetObjectWithVersionId = TrueJobsender会比对 versionId,并且发送SQS带真实 versionId。此时已经有真实的 versionId了,就没必要启用worker UpdateVersionId了,节省时间和请求数。
对于觉得没必要比对文件 version,文件传输过程中也不会被替换,或者没有源S3的 GetObjectVersion 权限,则三个开关都设置False即可(默认情况)
为什么不默认就把所有开关全部打开
- 速度问题:获取源S3 List VersionId 列表,会比只获取 Object 列表慢的多,如果文件很多(例如1万条记录以上),又是 Lambda 做 Jobsender 则可能会超过15分钟限制。
- 权限问题:不是所有桶都会开放 GetObjectVersion 权限。例如某些 OpenDataSet 即使打开了 Versioning 功能,但却没有开放 GetObjectVersion 权限。
局限与提醒
所需内存 = 并发数 * ChunckSize 。小于50GB的文件,ChunckSize为5MB,大于50GB的文件,则ChunkSize会自动调整为约等于: 文件Size/10000。
例如如果平均要处理的文件 Size 是 500GB ,ChunckSize 会自动调整为50MB,并发设置是 5 File x 10 Concurrency/File = 50,所以需要的EC2或Lambda的可运行内存约为 50 x 50MB = 2.5GB。 如需要提高并发度,可以调整配置,但对应的EC2或Lambda内存也要相应增加。CDK 默认配置的是EC2启动之后,自动通过 Userdata 脚本去yum安装 python,pip安装boto3, CloudwatchAgent,以及下载S3上面的代码和配置。
另外,如果你在中国区部署EC2,下载boto3, CWAgent的速度会慢,建议放到自己的S3上面,或不用userdata(包括jobsender和worker),而是自己手工部署,然后打包成AMI给EC2启动。不要在开始数据复制之后修改Chunksize。
删除资源则 cdk destroy 。
另外 DynamoDB、CloudWatch Log Group 、自动新建的 S3 bucket 需要手工删除
License
This library is licensed under the MIT-0 License. See the LICENSE file.