
|
|
3 năm trước cách đây | |
|---|---|---|
| .. | ||
| data | 3 năm trước cách đây | |
| data_processing | 3 năm trước cách đây | |
| final_data | 3 năm trước cách đây | |
| static | 3 năm trước cách đây | |
| templates | 3 năm trước cách đây | |
| .gitignore | 3 năm trước cách đây | |
| Pipfile | 3 năm trước cách đây | |
| Pipfile.lock | 3 năm trước cách đây | |
| Procfile | 3 năm trước cách đây | |
| README.md | 3 năm trước cách đây | |
| application.py | 3 năm trước cách đây | |
| panel1.png | 3 năm trước cách đây | |
| panel2.png | 3 năm trước cách đây | |
| panel3.png | 3 năm trước cách đây | |
| requirements.txt | 3 năm trước cách đây | |
| runtime.txt | 3 năm trước cách đây | |
| screenshot-xkcd-data-visualization.png | 3 năm trước cách đây | |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
README.md
Xkcd Data Visualization
A natural language processing and data visualization project.
hosted at: https://xkcd-data.herokuapp.com/
Overview
This single-page web application lets users interact with xkcd comics clustered by similarity. In the course of building this project, I learned how to clean data, use different natural language analysis techniques, build an interactive and reactive data visualization, and host a web application.
Feature Distribution
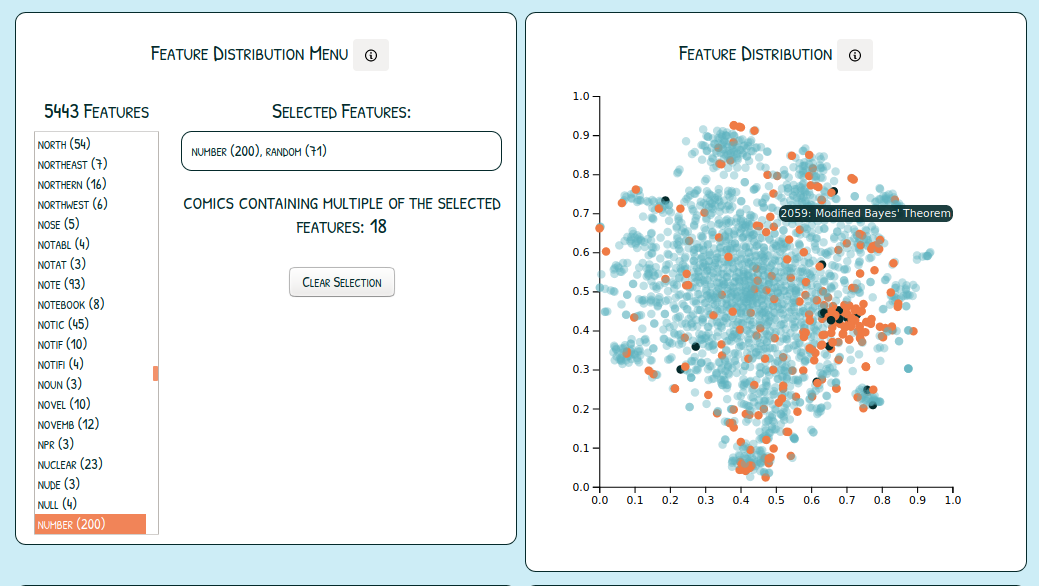
Users can select multiple features and see their full distribution over the t-sne plots (orange dots). This allows users too see what the total sum of the feature is coming from (blue bar in TFIDF bar chart). If multiple features are selected, comics with multiple selected features are highlighted (black dots).
Brushable Scatterplot of Comic Relations and TFIDF Values of Top 30 Words in Values Selected by Brush
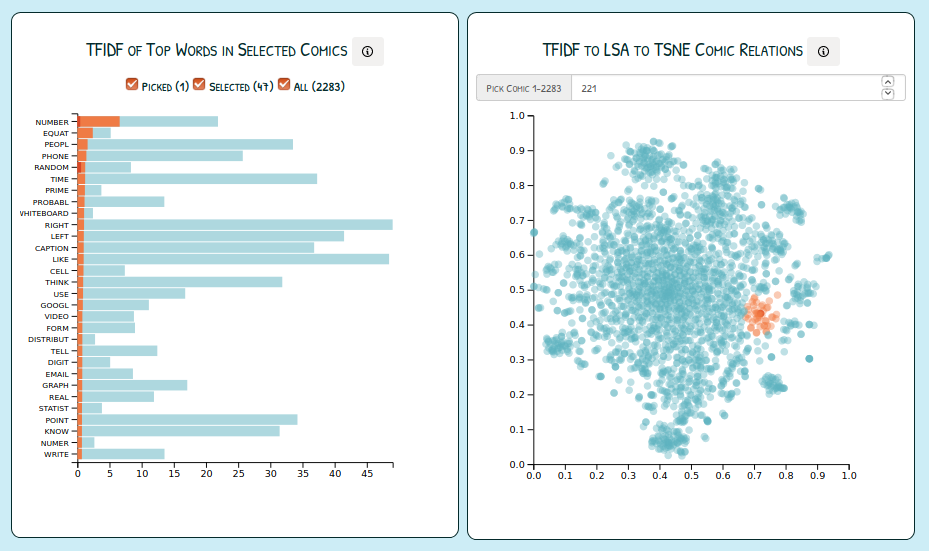
Users can drag and click to select and zoom on scatterplot. On brush event, the barchart is populated with summed TFIDF values of comic picked on click, comics selected by brush, and total TFIDF value of top 30 values.
Selected Comic Panel

See what comic you have clicked on in order to visually compare comics.
Background Information on Xkcd Comics
xkcd comics are "A webcomic of romance, sarcasm, math, and language" (xkcd slogan). These comics are licensed under a Creative Commons Attribution-NonCommercial 2.5 License, and their transcripts are available on www.explainxkcd.com (xkcd comic's wiki). This web application uses the first 2283 comics as data source.
Process
Languages:
- Python
- Javascript
Step 1: Save Comics Transcript, Title, And Alt-Text
beautifulsoup for text-scrapping html from www.explainxkcd.com (xkcd comic's wiki)
Step 2: Save Comic As Text Vectors of TF-IDF Scores
nltk's SnowballStemmer and spacy's Lemminizer for text-cleaning to increase coherency and reduce number of dimension
- lemminize and stem to make words with the same root e.g. a stemming algorithm reduces the words “chocolates”, “chocolatey”, “choco” to the root word, “chocolate” and “retrieval”, “retrieved”, “retrieves” reduce to the stem “retrieve”.
- clean contractions
- remove words that are less than 3 characters long
- remove punctuation, non-english characters, and characters that occur more than three in a row ("wooo" --> "wo")
- SnowballStemmer is a moderately aggressive stemmer
sklearn's Tfidfvectorizer for feature extraction
- compute word counts, idf and tf-idf values
- if word occurs in more than 70% of texts, cutoff
- if word does not occur in at least 2 documents, cutoff
- number of dimensions is (number of comics x number of unique words)
TF-IDF (term frequency-inverse document frequency) is a statistical measure that evaluates how relevant a word is to a document in a collection of documents. This is done by multiplying two metrics: how many times a word appears in a document, and the inverse document frequency of the word across a set of documents. This downweights words that are common to most of the documents as those very frequent terms would shadow the frequencies of rarer yet more interesting terms.
Step 3: Create 2D Embedding of Document Relations
sklearn's Truncated SVD for reducing the feature space and perform latent semantic analysis
- use truncated singular value decomposition (SVD) to reduce data from 7501 dimensions (words) to 50 dimension (features) that capture most of the variance of the data
- When truncated SVD is applied to term-document matrices (as returned by TfidfVectorizer), it is known as latent semantic analysis (LSA),because it transforms such matrices to a “semantic” space of low dimensionality
- In particular, LSA is known to combat the effects of synonymy and polysemy
sklearn's TSNE for building document relations expressed as corrdinates in the 2D plane
TSNE (t-distributed Stochastic Neighbor Embedding) is a tool to visualize high-dimensional data in a 2D plane, where similar comics turn into neighboring points.
- cost function: minimizes the divergence between two distributions, a distribution that measures pairwise similarities of the input objects and a distribution that measures pairwise similarities of the corresponding low-dimensional points in the embedding
- stochastic: probalistic (based on Gaussian distributions), gives a different outcome every time it runs
- t-distribution: preserves small distances inside clusters, prevents overlaping in dense clusters. Since it preserves smaller distances (as compared to PCA or SVD which aims to minimize variance) so it preserves local structures well
- very computationally heavy, so using another dimension reduction technique (PCA, SVD, etc.) to reduce dimensions to 50 before using TSNE is highly recommended
Step 4: Build Interactive Web Application To Explore Documnent Relationships**
d3.js for front-end, data visualization and event-behavior (click, hover, zoom, etc.)
Flask as a web server; since the tf-idf values are stored in scipy sparse matrix, summing and slicing the arrays are efficient and fast if the operations are in Python.
Bootstrap for building reactive web layout.