
ARCHITECTURE.md 9.7 KB
Architecture
Index
- Design Principles
- Core Components
- High-level Overview
- User Interface
- Persistence Layer
- Deletion Job Workflow
- See Also
Design Principles
The goal of the solution is to provide a secure, reliable, performant and cost effective tool for finding and removing individual records within objects stored in S3 buckets. In order to achieve these goals the solution has adopted the following design principles:
- Secure by design:
- Every component is implemented with least privilege access
- Encryption is performed at all layers at rest and in transit
- Authentication is provided out of the box
- Expiration of logs is configurable
- Record identifiers (known as Match IDs) are automatically obfuscated or irreversibly deleted as soon as possible when persisting state
- Built to scale: The system is designed and tested to work with petabyte-scale Data Lakes containing thousands of partitions and hundreds of thousands of objects
- Cost optimised:
- Perform work in batches: Since the time complexity of removing a single vs multiple records in a single object is practically equal and it is common for data owners to have the requirement of removing data within a given timeframe, the solution is designed to allow the solution operator to "queue" multiple matches to be removed in a single job.
- Fail fast: A deletion job takes place in two distinct phases: Find and Forget. The Find phase queries the objects in your S3 data lakes to find any objects which contain records where a specified column contains at least one of the Match IDs in the deletion queue. If any queries fail, the job will abandon as soon as possible and the Forget phase will not take place. The Forget Phase takes the list of objects returned from the Find phase, and deletes only the relevant rows in those objects.
- Optimised for Parquet: The split phase approach optimises scanning for columnar dense formats such as Parquet. The Find phase only retrieves and processes the data for relevant columns when determining which S3 objects need to be processed in the Forget phase. This approach can have significant cost savings when operating on large data lakes with sparse matches.
- Serverless: Where possible, the solution only uses Serverless components to avoid costs for idle resources. All the components for Web UI, API and Deletion Jobs are Serverless (for more information consult the Cost Overview guide).
- Robust monitoring and logging: When performing deletion jobs, information is provided in real-time to provide visibility. After the job completes, detailed reports are available documenting all the actions performed to individual S3 Objects, and detailed error traces in case of failures to facilitate troubleshooting processes and identify remediation actions. For more information consult the Troubleshooting guide.
Core components
The following terms are used to identify core components within the solution.
Data Mappers
Data Mappers instruct the Amazon S3 Find and Forget solution how and where to search for items to be deleted.
To find data, a Data Mapper uses:
- A table in a supported data catalog provider which describes the location and structure of the data you want to connect to the solution. Currently, AWS Glue is the only supported data catalog provider.
- A query executor which is the service the Amazon S3 Find and Forget solution will use to query the data. Currently, Amazon Athena is the only supported query executor.
Data Mappers can be created at any time, and removed when no deletion job is running.
Deletion Queue
The Deletion Queue is a list of matches. A match is a value you wish to search for, which identifies rows in your S3 data lake to be deleted. For example, a match could be the ID of a specific customer.
Matches can be added at any time, and can be removed only when no deletion job is in progress.
Deletion Jobs
A Deletion Job is an activity performed by Amazon S3 Find and Forget which queries your data in S3 defined by the Data Mappers and deletes rows containing any match present in the Deletion Queue.
Deletion jobs can be run anytime there is not another deletion job already running.
High-level Overview
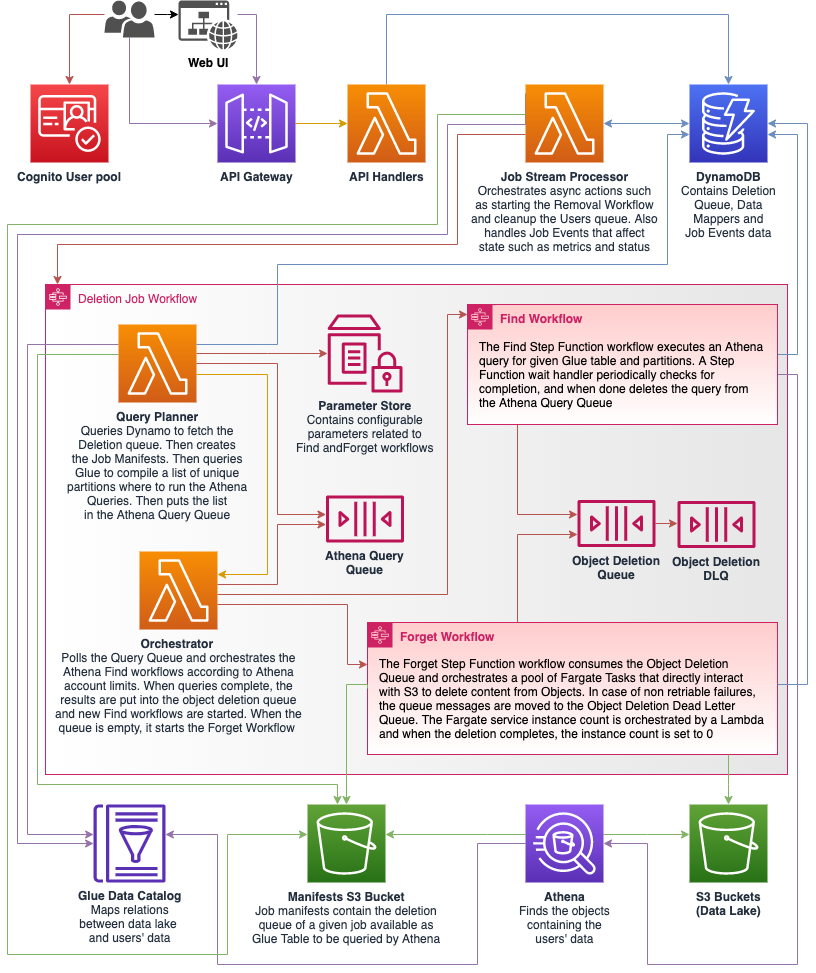
User Interface
Interaction with the system is via the Web UI or the API.
To use the Web UI customers must authenticate themselves. The Web UI uses the same Amazon Cognito User Pool as the API. It consists of an Amazon S3 static site hosting a React.js web app, optionally distributed by an Amazon CloudFront distribution, which makes authenticated requests to the API on behalf of the customer. Customers can also send authenticated requests directly to the API Gateway (API specification).
Persistence Layer
Data Persistence is handled differently depending on the cirumstances:
- The customer performs an action that synchronously affects state such as making an API call that results on a write or update of a document in DynamoDB. In that case the Lambda API Handlers directly interact with the Database and respond accordingly following the API specification.
- The customer performs an action that results in a contract for a asynchronous promise to be fullfilled such as running a deletion Job. In that case, the synchronous write to the database will trigger an asynchronous Lambda Job Stream Processor that will perform a variety of actions depending on the scenario, such as executing the Deletion Job Step Function. Asynchronous actions generally handle state by writing event documents to DynamoDB that are occasionally subject to further actions by the Job Stream Processor.
The data is stored in DynamoDB using 3 tables:
- DataMappers: Metadata for mapping S3 buckets to the solution.
- DeletionQueue: The queue of matches to be deleted. This data is stored in DynamoDB in order to provide an API that easily allows to inspect and occasionally amend the data between deletion jobs.
- Jobs: Data about deletion jobs, including the Job Summary (that contains an up-to-date representation of specific jobs over time) and Job Events (documents containing metadata about discrete events affecting a running job). Job records will be retained for the duration specified in the settings after which they will be removed using the DynamoDB TTL feature.
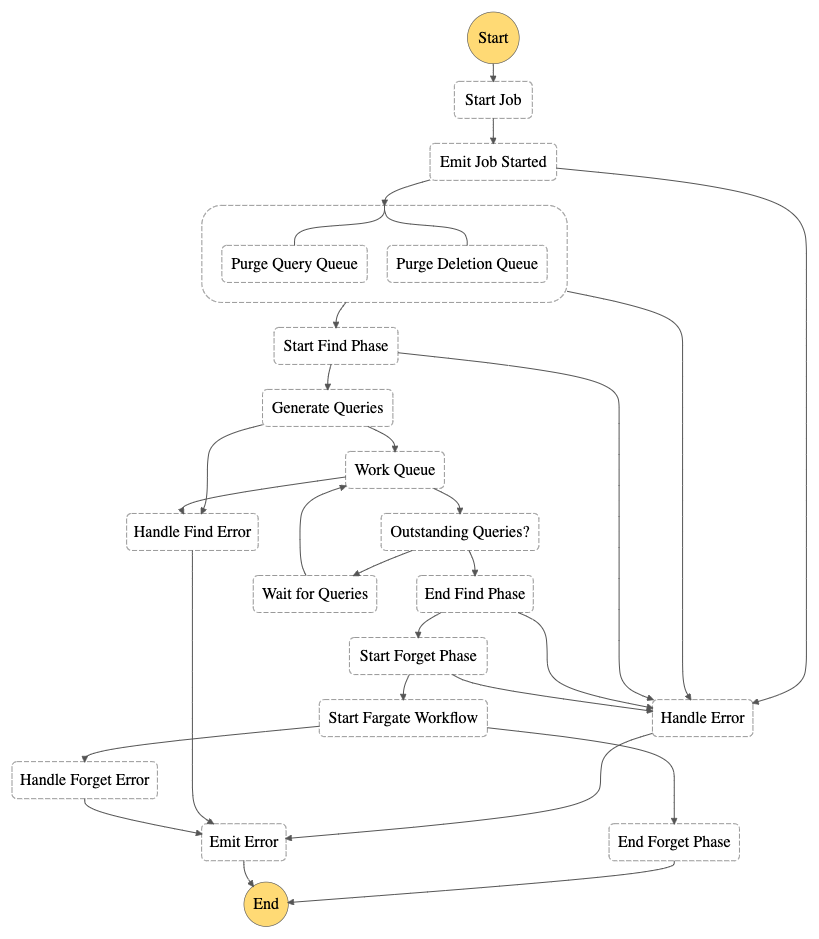
Deletion Job Workflow
The Deletion Job workflow is implemented as an AWS Step Function.
When a Deletion Job starts, the solution gathers all the configured data mappers then proceeds to the Find phase.
For each supported query executor, the workflow generates a list of queries it should run based on the data mappers associated with that query executor and the partitions present in the data catalog tables associated with those data mappers. For each generated query, a message containing the required information required by the target query executor is added to the query queue.
When all the queries have been executed, the Forget Workflow is executed.
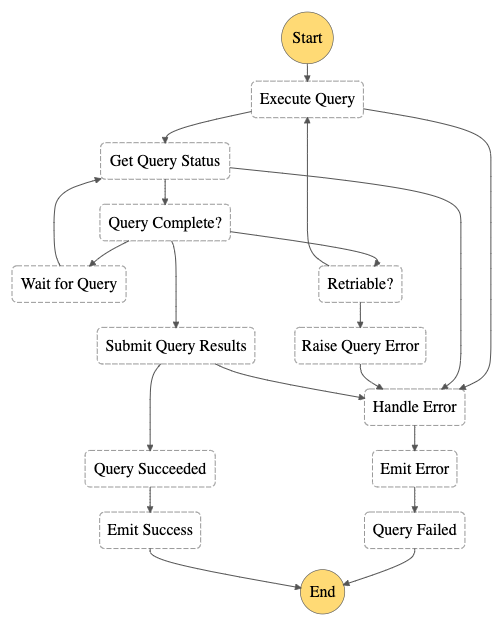
The Athena Find Workflow
The Amazon S3 Find and Forget solution currently supports one type of Find Workflow, operated by an AWS Step Function that leverages Amazon Athena to query Amazon S3.
The workflow is capable of finding where specific content is located in Amazon
S3 by using Athena's $path pseudo-parameter as part of each query. In this way
the system can operate the Forget Workflow by reading/writing only relevant
objects rather than whole buckets, optimising performance, reliability and cost.
When each workflow completes a query, it stores the result to the Object
Deletion SQS Queue. The speed of the Find workflow depends on the Athena
Concurrency (subject to account limits) and wait handlers, both configurable
when deploying the solution.
The Forget Workflow
The Forget workflow is operated by a Amazon Step Function that uses AWS Lambda and AWS Fargate for computing and Amazon DynamoDB and Amazon SQS to handle state.
When the workflow starts, a fleet of AWS Fargate tasks is instantiated to consume the Object Deletion Queue and start deleting content from the objects. When the Queue is empty, a Lambda sets the instances back to 0 in order to optimise cost. The number of Fargate tasks is configurable when deploying the solution.
Note that during the Forget phase, affected S3 objects are replaced at the time they are processed and are subject to the Amazon S3 data consistency model. We recommend that you avoid running a Deletion Job in parallel to a workload that reads from the data lake unless it has been designed to handle temporary inconsistencies between objects.
