
|
|
há 3 anos atrás | |
|---|---|---|
| .. | ||
| .dependabot | há 3 anos atrás | |
| .github | há 3 anos atrás | |
| backend | há 3 anos atrás | |
| ci | há 3 anos atrás | |
| docs | há 3 anos atrás | |
| frontend | há 3 anos atrás | |
| templates | há 3 anos atrás | |
| tests | há 3 anos atrás | |
| .dockerignore | há 3 anos atrás | |
| .gitignore | há 3 anos atrás | |
| .pre-commit-config.yaml | há 3 anos atrás | |
| .pylintrc | há 3 anos atrás | |
| CHANGELOG.md | há 3 anos atrás | |
| CODE_OF_CONDUCT.md | há 3 anos atrás | |
| CONTRIBUTING.md | há 3 anos atrás | |
| LICENSE | há 3 anos atrás | |
| Makefile | há 3 anos atrás | |
| NOTICE | há 3 anos atrás | |
| README.md | há 3 anos atrás | |
| cfn-publish.config | há 3 anos atrás | |
| docker_run_with_creds.sh | há 3 anos atrás | |
| package-lock.json | há 3 anos atrás | |
| package.json | há 3 anos atrás | |
| pytest.ini | há 3 anos atrás | |
| requirements.in | há 3 anos atrás | |
| requirements.txt | há 3 anos atrás | |
README.md
Amazon S3 Find and Forget



Warning: Consult the Production Readiness guidelines prior to using the solution with production data
Amazon S3 Find and Forget is a solution to the need to selectively erase records from data lakes stored on Amazon Simple Storage Service (Amazon S3). This solution can assist data lake operators to handle data erasure requests, for example, pursuant to the European General Data Protection Regulation (GDPR).
The solution can be used with Parquet and JSON format data stored in Amazon S3 buckets. Your data lake is connected to the solution via AWS Glue tables and by specifying which columns in the tables need to be used to identify the data to be erased.
Once configured, you can queue record identifiers that you want the corresponding data erased for. You can then run a deletion job to remove the data corresponding to the records specified from the objects in the data lake. A report log is provided of all the S3 objects modified.
Installation
The solution is available as an AWS CloudFormation template and should take about 20 to 40 minutes to deploy. See the deployment guide for one-click deployment instructions, and the cost overview guide to learn about costs.
Usage
The solution provides a web user interface, and a REST API to allow you to integrate it in your own applications.
See the user guide to learn how to use the solution and the API specification to integrate the solution with your own applications.
Architecture
The goal of the solution is to provide a secure, reliable, performant and cost effective tool for finding and removing individual records within objects stored in S3 buckets. In order to achieve this goal the solution has adopted the following design principles:
- Secure by design:
- Every component is implemented with least privilege access
- Encryption is performed at all layers at rest and in transit
- Authentication is provided out of the box
- Expiration of logs is configurable
- Record identifiers (known as Match IDs) are automatically obfuscated or irreversibly deleted as soon as possible when persisting state
- Built to scale: The system is designed and tested to work with petabyte-scale Data Lakes containing thousands of partitions and hundreds of thousands of objects
- Cost optimised:
- Perform work in batches: Since the time complexity of removing a single vs multiple records in a single object is practically equal and it is common for data owners to have the requirement of removing data within a given timeframe, the solution is designed to allow the solution operator to "queue" multiple matches to be removed in a single job.
- Fail fast: A deletion job takes place in two distinct phases: Find and Forget. The Find phase queries the objects in your S3 data lakes to find any objects which contain records where a specified column contains at least one of the Match IDs in the deletion queue. If any queries fail, the job will abandon as soon as possible and the Forget phase will not take place. The Forget Phase takes the list of objects returned from the Find phase, and deletes only the relevant rows in those objects.
- Optimised for Parquet: The split phase approach optimises scanning for columnar dense formats such as Parquet. The Find phase only retrieves and processes the data for relevant columns when determining which S3 objects need to be processed in the Forget phase. This approach can have significant cost savings when operating on large data lakes with sparse matches.
- Serverless: Where possible, the solution only uses Serverless components to avoid costs for idle resources. All the components for Web UI, API and Deletion Jobs are Serverless (for more information consult the Cost Overview guide).
- Robust monitoring and logging: When performing deletion jobs, information is provided in real-time to provide visibility. After the job completes, detailed reports are available documenting all the actions performed to individual S3 Objects, and detailed error traces in case of failures to facilitate troubleshooting processes and identify remediation actions. For more information consult the Troubleshooting guide.
High-level overview diagram
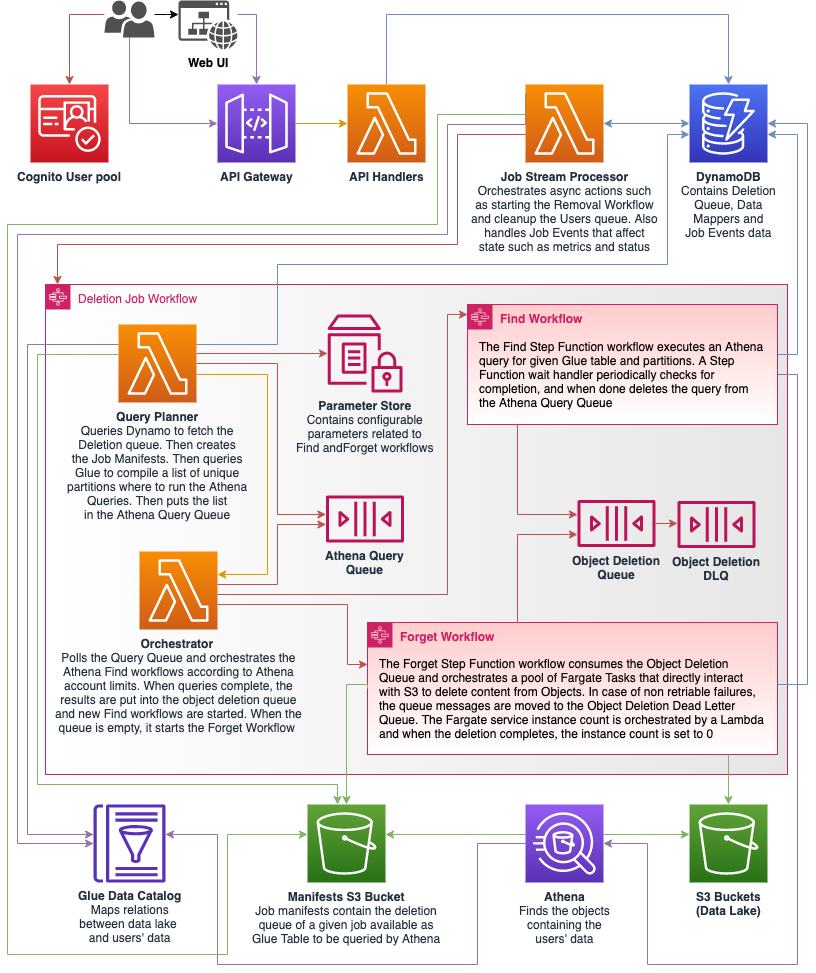
See the Architecture guide to learn more about the architecture.
Documentation
- User Guide
- Deployment
- Architecture
- Troubleshooting
- Monitoring the Solution
- Security
- Cost Overview
- Limits
- API Specification
- Local Development
- Production Readiness guidelines
- Change Log
- Upgrade Guide
Contributing
Contributions are more than welcome. Please read the code of conduct and the contributing guidelines.
License Summary
This project is licensed under the Apache-2.0 License.