|
|
před 3 roky | |
|---|---|---|
| .. | ||
| screenshots | před 3 roky | |
| templates | před 3 roky | |
| .gitignore | před 3 roky | |
| LICENSE | před 3 roky | |
| README.md | před 3 roky | |
| fetch_links.py | před 3 roky | |
| write_html.py | před 3 roky | |
README.md
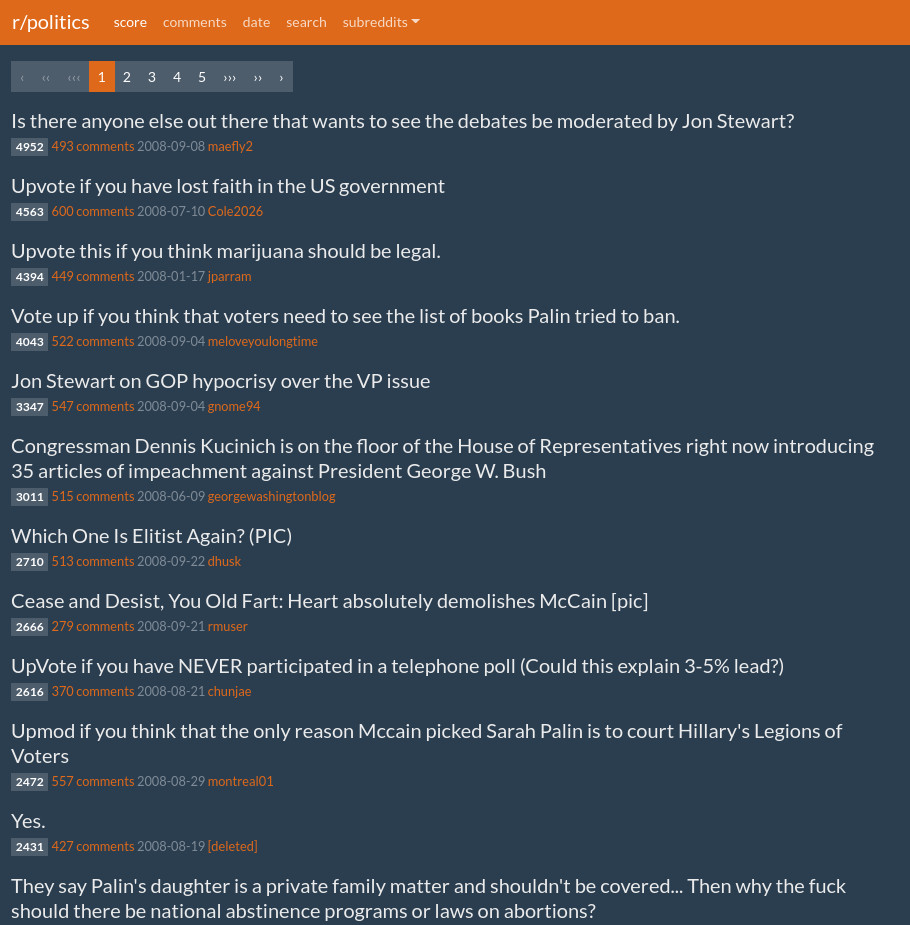
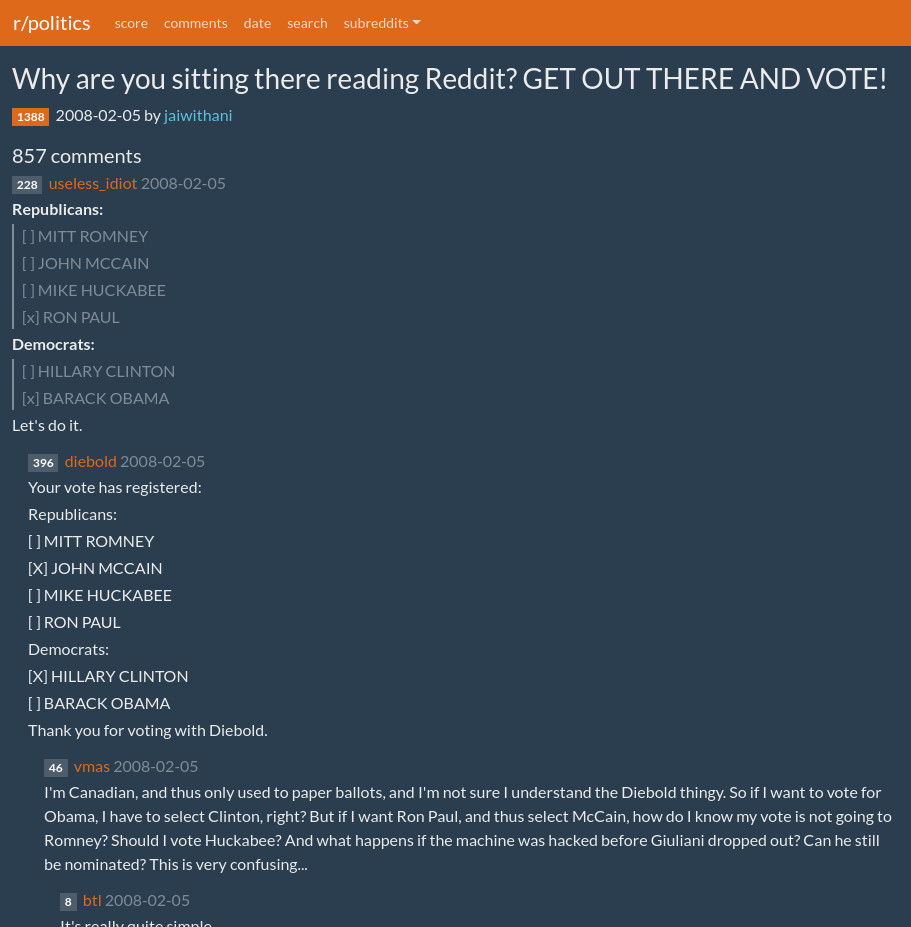
reddit html archiver
pulls reddit data from the pushshift api and renders offline compatible html pages. uses the reddit markdown renderer.
install
requires python 3 on linux, OSX, or Windows.
warning: if $ python --version outputs a python 2 version on your system, then you need to replace all occurances of python with python3 in the commands below.
$ sudo apt-get install pip
$ pip install psaw -U
$ git clone https://github.com/chid/snudown
$ cd snudown
$ sudo python setup.py install
$ cd ..
$ git clone [this repo]
$ cd reddit-html-archiver
$ chmod u+x *.py
Windows users may need to run
> chcp 65001
> set PYTHONIOENCODING=utf-8
before running fetch_links.py or write_html.py to resolve encoding errors such as 'codec can't encode character'.
fetch reddit data
fetch data by subreddit and date range, writing to csv files in data:
$ python ./fetch_links.py politics 2017-1-1 2017-2-1
or you can filter links/posts to download less data:
$ python ./fetch_links.py --self_only --score "> 2000" politics 2015-1-1 2016-1-1
to show all available options and filters run:
$ python ./fetch_links.py -h
decrease your date range or adjust pushshift_rate_limit_per_minute in fetch_links.py if you are getting connection errors.
write web pages
write html files for all subreddits to r:
$ python ./write_html.py
you can add some output filtering to have less empty postssmaller archive size
$ python ./write_html.py --min-score 100 --min-comments 100 --hide-deleted-comments
to show all available filters run:
$ python ./write_html.py -h
your html archive has been written to r. once you are satisfied with your archive feel free to copy/move the contents of r to elsewhere and to delete the git repos you have created. everything in r is fully self contained.
to update an html archive, delete everything in r aside from r/static and re-run write_html.py to regenerate everything.
hosting the archived pages
copy the contents of the r directory to a web root or appropriately served git repo.
potential improvements
- fetch_links
- num_comments filtering
- thumbnails or thumbnail urls
- media posts
- score update
- scores from reddit with praw
- real templating
- choose Bootswatch theme
- specify subreddits to output
- show link domain/post type
- user pages
- add pagination, posts sorted by score, comments, date, sub
- too many files in one directory
- view on reddit.com
- js powered search page, show no links by default
- js inline media embeds/expandos
- archive.org links
see also
screenshots